深度解析GLM-5.1:8小时持续工作背后的技术架构与工程突破
2026年4月10日,智谱发布新一代旗舰模型GLM-5.1。这是国产开源模型首次在SWE-benchPro基准测试中超越ClaudeOpus4.6,标志着国内大模型技术正式进入全球第一梯队。作为一名长期关注AI发展的技术从业者,我亲眼见证了这场技术跃迁的全过程。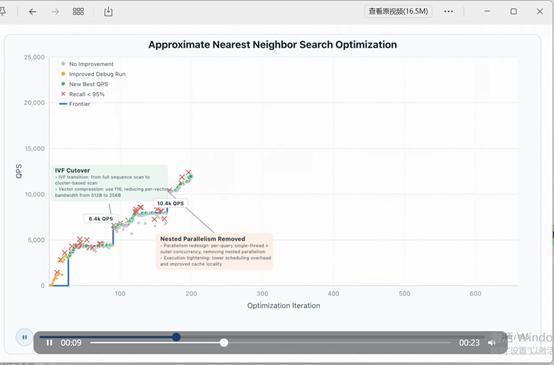
从分钟级到小时级:大模型工作模式的范式转变
过去两年,业界普遍用Benchmark衡量模型的智能水平。这种方法论在模型发展的初级阶段是有效的,它帮助我们快速判断模型的通用能力。然而,随着模型能力的不断提升,Benchmark的局限性愈发明显——它只能告诉我们模型“有多聪明”,却无法反映模型在实际复杂任务中的表现。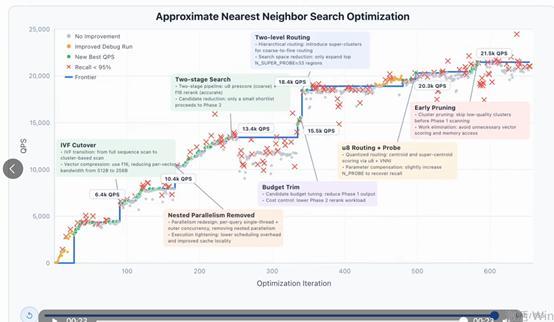
2025年3月,AI安全研究机构METR提出了一个改变行业认知的指标:任务完成时间线(Task-CompletionTimeHorizon)。这个指标不再衡量模型答对多少道题,而是衡量模型能独立完成多长时间的人类任务。研究数据显示,前沿模型的时间线每7个月翻一倍。这条指数曲线被MITTechnologyReview称为“AI领域最重要的一张图”。
GLM-5.1的技术架构解析
GLM-5.1的核心突破在于其长程任务能力。与此前分钟级交互的模型不同,它能够在一次任务中独立、持续工作超过8小时,期间自主规划、执行、自我进化,最终交付完整的工程级成果。
实现这一能力的技术难点在于:模型面对的不只是更大代码量,而是一连串复杂的工程决策点。主动跑benchmark、定位瓶颈、修改方案、再跑测试——这要求模型形成“实验→分析→优化”的完整闭环,而不是写完代码停下来等人打分。
实测数据揭示的真实性能
我用开发者工具对GLM-5.1进行了实测。测试案例是一个专门考验AI编程能力的任务:让AI开发一个能快速检索海量数据的系统。此前最强的成绩由ClaudeOpus4.6创造。实测结果显示,GLM-5.1在持续进行六百多次优化、六千多次操作后,性能还在不断提升,最终速度达到了之前最好成绩的6倍。
在业内最具代表性的三个代码评测基准中,包括SWE-BenchPro、Terminal-Bench2.0、NL2Repo,GLM-5.1取得全球模型第三、国产模型第一、开源模型第一的成绩。
从价格战到价值定价:国产大模型的商业化拐点
值得关注的是,智谱GLM再度提价10%,编码场景定价首次追平海外头部厂商Anthropic。这标志着国产大模型从“低价换量”转向“性能溢价”的战略升级。
智谱CEO张鹏对此的解释颇具深意:完成一个长程任务所需要的Token量可能是回答一个简单问题时的十倍甚至百倍,价格调整本质上是价值变化的自然结果。这一论述揭示了大模型商业化的本质逻辑:模型能力的提升必然带来价值重新定价。
数据显示,2026年一季度智谱API调用定价提升83%,即便如此市场依然供不应求,调用量增长400%。这印证了一个基本判断:当模型能力足够强时,用户愿意为价值买单,而非单纯追求低价。

